
Why “Average Accuracy” Is a Dangerous Metric for Healthcare AI Agents

If you are building AI agents for the healthcare industry, you have likely already accepted that “average accuracy” is a misleading comfort metric.
A Hard Lesson from the Field
We experienced this firsthand while building Zealth(YC W21). We spent over a year securing a pilot with one of the largest cancer hospitals in India. By that time, more than 700 oncology patients were already using our chatbot to get quick and personalized answers to non-medical queries.
Despite this, a single conversation that violated guardrails led to immediate consequences. Although we intervened right away and resolved the situation, we lost the hospital partnership without being given the opportunity to fix the system. That’s the cost of error while building an AI Agent for healthcare, making evals and particularly guardrails testing in the pre-production phase all the more important.
Healthcare AI Is Going Mainstream, Reliability Is the Real Question
With Claude and OpenAI making healthcare a mainstream use case for understanding personal health and improving communication efficiency with the providers, the more important question becomes: how can I use these systems for my specific use case, reliably?
Improving conversation between doctors and patients
Claude can summarize a user’s medical history, explain test results in plain language, detect patterns across fitness and health metrics, and help prepare questions for medical appointments. These are valuable capabilities.
Where Things Get Fragile : It is critical to understand how such systems perform when test results indicate the possibility of something serious, such as cancer or a lifelong condition. These situations require sensitive communication that must vary across different ages, demographics, and patient personas. This also includes handling the follow-up questions that naturally arise after results are explained in plain language, especially when discussing uncertainty, probabilities, and next steps. While such communication is ideally handled in person, it is important for the AI agent to understand whether the patient is already aware of their condition. The way this information is communicated must differ based on that context.
Co-ordinating care and triaging patient messages
OpenAI for Healthcare helps clinical teams search medical evidence, align decisions with care pathways, draft referrals and discharge documents, and support care coordination workflows without automating patient triage or clinical decision-making.
The Challenge : A key challenge in this area is accounting for cultural and linguistic nuances in how patients from different backgrounds communicate symptoms and concerns.
For example, last year, my mother in northern India said “jee ghabra raha hai” (a Hindi expression commonly used to describe nausea or general discomfort). A doctor who did not natively speak Hindi misinterpreted this as palpitations due to the cultural nuance of the word “jee.”
While such misunderstandings already occur at a human level, AI agents must be explicitly tested for these scenarios to avoid amplifying errors in clinical workflows.
So How Do Teams Test Healthcare AI Today?
That is the hard part.
Most healthcare AI agent builders rely on teams of clinicians who continuously create test scenarios to evaluate agents for edge cases before they occur with real patients. These scenarios are then run against the agents, either through synthetic generation or human adversarial testing, to assess agent behaviour. They are designed to capture a wide range of layperson and healthcare provider personas, span multiple medical specialties and contexts, and are deliberately selected for difficulty.
OpenAI introduced HealthBench, a new benchmark designed to better measure the capabilities of AI systems in healthcare.
HealthBench is developed in partnership with 262 physicians who have practiced in 60 countries. It includes 5,000 realistic health conversations, each paired with a custom, physician-created rubric to evaluate model responses. These conversations simulate interactions between AI systems and individual users or clinicians. HealthBench covers evaluation across a variety of scenarios such as emergency referrals, responding under uncertainty, global health, and context seeking and evaluates dimensions like communication quality, instruction following, and completeness.
While this is a meaningful step forward, most healthcare organizations building AI agents still rely on internally created clinical scenarios. The evaluation requirements for a mental health agent versus a personal health assistant differ fundamentally in terms of risk, conversational sensitivity, and failure modes. These differences compound further across geographies, languages, cultural norms, and regulatory regimes, making it impossible for a single benchmark to capture the full complexity required for real-world deployment.
Why Testing Breaks at Scale
When teams first start building agents, manual testing, dogfooding, and intuition are often enough. The system is small, changes are infrequent, and failures are easy to spot.
Once an agent reaches production and begins to scale, this approach breaks down. The number of possible user paths grows rapidly, conversations become longer and stateful, and changes ship continuously across prompts, models, tools, and memory. Ownership fragments across teams, and no single person retains a complete mental model of the system.
At this point, failures are no longer obvious or repeatable. Safety, correctness, and user experience become probabilistic rather than guaranteed. Informal testing stops working not because teams are careless, but because intuition cannot keep up with the expanding surface area of risk.
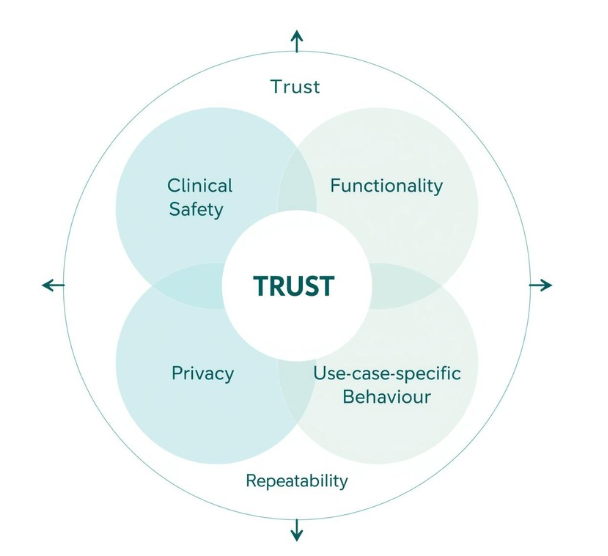
Deepdive into Core Evaluation Dimensions for Healthcare AI Agents
- Clinical safety : This includes ensuring the agent does not provide diagnoses even when explicitly asked, does not offer medical advice intended to be given only by licensed practitioners, and appropriately deflects or escalates sensitive clinical queries. Typically, the clinical team owns the definition of these scenarios, the expected behavior, and the failure criteria. In our experience, these evaluations are usually binary in nature, with clearly defined pass or fail outcomes.
- Functionality : This covers scenarios such as handling cultural nuances discussed earlier, users providing incomplete information, users clarifying health details mid-conversation, and users asking follow-up questions about a condition. In our experience, the product team typically owns the definition of scenarios and evaluations in this category. These are often harder to define as binary pass or fail outcomes and are usually analyzed at the conversation transcript level, with tags used to identify specific “moments” and assess agent behaviour in context.
- Privacy : This includes scenarios where users unintentionally share personally identifiable information (PII) or protected health information (PHI), as well as more critical cases where unauthorized individuals attempt to request or access PHI. Typically, the security or compliance team defines the evaluation criteria, while scenarios are created by the product team, with clear pass or fail conditions.
- Use-case-specific behaviour : For example, in the case of Zealth, an oncology-focused agent, we supported region-specific diet and recipe recommendations that were high in protein and tailored to the cultural context and staple foods of each region. These evaluations are typically owned by the technical or product teams. A common pattern involves identifying a specific transcript or scenario from user analytics that needs to be tested. In our experience, such scenarios are often used to recreate conversations that occurred in production, either to re-evaluate behavior after an agent change or to deeply analyze agent performance. One of the biggest challenges here is recreating the correct agent state before running the scenario; this is discussed further below.
- Repeatability : A key metric here is pass^k, which measures the probability that all k trials succeed. As k increases, pass^k decreases, since requiring consistency across multiple trials sets a higher bar. For example, if an agent has a 90% per-trial success rate and three trials are run, the probability of passing all three is (0.9)³ ≈ 73%. This metric is especially important for healthcare agents, where users expect reliable behavior every time. Ensuring repeatability is typically owned by the AI or engineering team, which is responsible for maintaining consistency across runs.
Additional complexity
Evaluation becomes more complex when testing state-dependent components such as the agent’s memory layer or tool calls. In these cases, scenarios must start from a standardized agent state; otherwise, results will not be repeatable, and it becomes impossible to compare performance before and after changes. Ensuring the agent is in the correct state before running a scenario is critical for making evaluation results meaningful.
How We Approach at UserTrace
At UserTrace, we are building infrastructure specifically for this problem.
UserTrace lets clinical and language experts create scenarios and evaluations without needing to understand LLM-judge prompts or evaluation mechanics. Over time, this builds a structured knowledge graph of scenarios and evals that evolves alongside the product.
From minimal input, UserTrace automatically generates realistic multi-turn conversations, edge cases, and complete evaluation flows.
For example, a prompt like “a 30-year-old migrant delivery worker in Singapore, feeling stressed and homesick” expands into representative scenarios with associated evaluations and personas for testing.
Teams connect their agent’s sandbox to UserTrace via APIs or standard interfaces such as SMS, voice, or WhatsApp, and run these scenarios to test clinical safety, functionality, and user experience.
Crucially, expert feedback from simulations feeds back into the system, continuously improving both the scenarios and the reliability of the evaluations over time.
If you wish to learn more, book a time with me.



